


Definitely, maybe finished support for iMX8MQ Vivante GPU
In this series of posts I am going to elaborate on porting the etnaviv driver to Genode and what this effort did entail. The fourth and for now last entry is about wrapping the project up and along the lines mending one or the other dent - namely increasing the performance.
Introduction
The last post was about introducing a Gpu session to the driver. With that in place the exploration was finished. In the meantime, however, the genode-imx repository got its finishing touches.
Up to now the etnaviv driver still resided on a topic branch and was only loosely following the new DDE Linux approach. For practical reasons it contained a copy of the old DDE Linux foundations, namely lx_kit and the lx_emul adapted for use with the more recent ARMv8 platform_drv interface. For the driver to get to its final home in the genode-imx repository this had to change.
A new hope^Whome
Since the driver was already using some of the utilities and, most importantly already depended on the vanilla Linux header files for all declarations and definitions - replacing the Linux emulation layer was straight forward. This undertaking was simplified because the already ported frame-buffer driver and the etnaviv driver share common parts of the DRM subsystem. So I could re-use parts of its source.list file that specifies each and every contrib source file referenced by the driver component.
At this stage I spent most of the time to check which functionality is already provided by the DDE, which parts I have to move over from the previous etnaviv driver port and which parts might need some adjustment. Most prominently I had to extended the Lx_kit::Memory interface to deal with the management of the DMA memory for the GPU buffer-objects. If you recall, the Gpu session hands out a dataspace-capability to its client to access the backing storage of the buffer-object. Therefore I had to get access to that. In the new DDE Linux emulation libraries the handling of DMA memory is nicely tucked away, even cached vs. uncached is properly dealt with, behind the usual Linux APIs.
That being said, there was no way to get hold of the dataspace-capability itself yet. After all, this was not something the other drivers have needed so far. Like with the previous etnaviv driver, the hook into the buffer-object allocation is with shmem_file_setup
struct shmem_file_buffer
{
void *addr;
struct page *pages;
};
struct file *shmem_file_setup(char const *name, loff_t size,
unsigned long flags)
{
struct file *f;
struct inode *inode;
struct address_space *mapping;
struct shmem_file_buffer *private_data;
[…]
private_data = kzalloc(sizeof (struct shmem_file_buffer), 0);
if (!private_data) {
goto err_private_data;
}
private_data->addr = emul_alloc_shmem_file_buffer(size);
if (!private_data->addr)
goto err_private_data_addr;
/*
* We call virt_to_pages eagerly here, to get contingous page
* objects registered in case one wants to use them immediately.
*/
private_data->pages =
lx_emul_virt_to_pages(private_data->addr, size >> 12);
mapping->private_data = private_data;
mapping->nrpages = size >> 12;
f->f_mapping = mapping;
[…]
return f;
Here emul_alloc_shmem_file_buffer is used to allocate the dataspace directly (via Lx_kit::Memory::allocate_dataspace) and lx_emul_virt_to_pages creates a page object for each 4K chunk (for better or worse the DRM subsystem wants handle it this way).
As before we use one allocation (⇒ one dataspace) for each buffer-object. During its allocation the backing memory is put into a map that allows for lookup by its virtual address. This is our way in:
Dataspace_capability Lx_kit::Mem_allocator::attached_dataspace_cap(void * addr)
{
Dataspace_capability ret { };
_virt_to_dma.apply(Buffer_info::Query_addr(addr),
[&] (Buffer_info const & info) {
ret = info.buffer.ds().cap();
});
return ret;
}
So, whenever the client request a new buffer we
-
execute lx_drm_ioctl_etnaviv_gem_new() to create a new buffer-object
-
lookup its offset (~= virtual address)
-
lookup its dataspace using the offset
-
return the dataspace capability to the client
—
lx_drm_ioctl_etnaviv_gem_new() is part of the small lx_drm shim that is put on top of drm_ioctl and presents a specially-tailored interface for use by the Gpu::Session_component implementation.
—
Again, all contrib code is executed within a task - by now kernel_thread() is called to create it rather than using the Lx_kit::Task API directly, which is scheduled whenever a client request comes in. The code for the Gpu::Session_component implementation was taken from the previous driver.
In addition to looking up a capability the Lx_kit::Memory got extended to allow for freeing backing memory, something that also was not needed until now.
Another noticeable change in the new driver is the way it is initialized. Formerly most parts of the OF/device-tree/device-component handling were hard-coded and the init function of the various subsystems were called manually. Now it relies on the init mechanism already implemented in the DDE and uses a stripped down device-tree to configure the kernel subsystems. In case of the etnaviv driver I had to specify two device-tree nodes, e.g.:
# Driver-specific device-tree binary data BOARDS := mnt_reform2 DTS_PATH(mnt_reform2) := arch/arm64/boot/dts/freescale/imx8mq-mnt-reform2.dts DTS_EXTRACT(mnt_reform2) := --select gpu --select pinctrl_i2c1
as tool/dts/extract would otherwise be unable to generate a working device-tree source file.
Pointing the emulation layer to the .dtb in lx_emul_start_kernel() gets the ball rolling, the gears spinning and the horse turning:
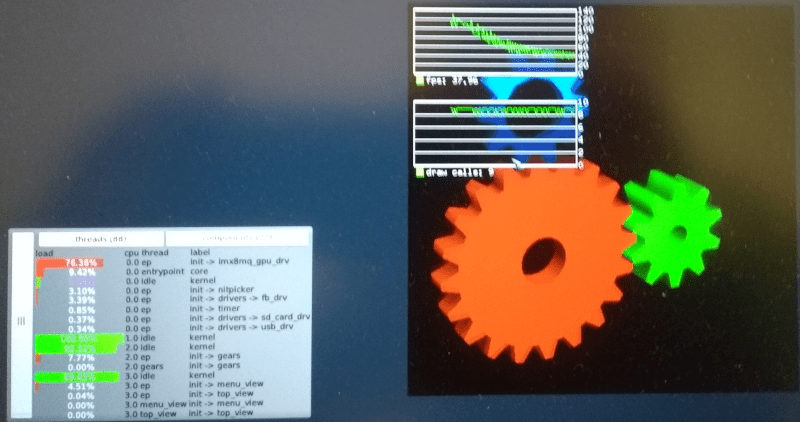
|
|
eglgears spinning round and roouund and rooouuuund…
|
Performance observations
Focusing on the Gallium HUD in the eglgears windows reveals something suspicious. Apparently the FPS are steadily decreasing. That looks odd. And judging by top_view the time spend in the driver component is increasing, yikes.
Especially in such a well-meaning test-case - after all the gears scene is mostly static and there are neither many primitives nor buffer-objects to begin with - the FPS should not be dropping.
Well, what is going on then? To eventually be able to pin down where things are going haywire I started to instrument the amount of cycles spend in each Gpu session RPC call. For that I employed the TSC LOG probes Norman used to instrument Sculpt's boot-up time.
After fitting each RPC call with such a probe it became obvious where most of the CPU cycles are burned: in exec_buffer. Curious but not entirely unexpected - there is not much explicit allocation going on and the (un-)mapping calls should be fairly consistent (reading from the CPU for blitting purposes).
—
For example exec_buffer was fitted like this:
Gpu::Sequence_number exec_buffer(Gpu::Buffer_id id,
Genode::size_t) override
{
GENODE_LOG_TSC_NAMED(60, "EXEC");
[…]
}
The rate of 60 pretty much hinting at which FPS I was expecting.
—
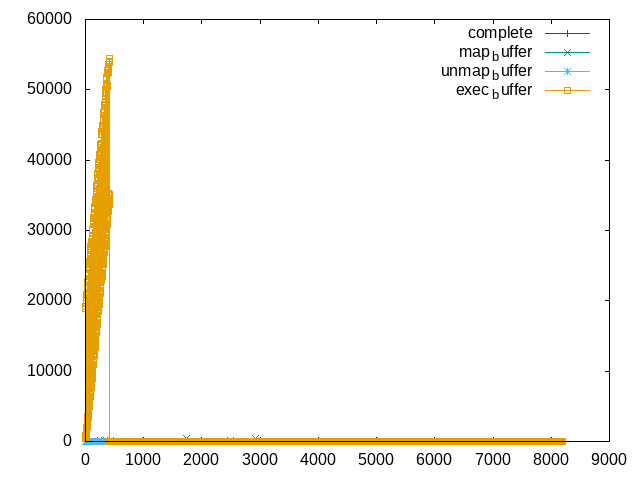
|
|
Totally scientific plot showing the (normalized) cycles (y-axis) spent in each RPC (the sample rate of the probes differs and in case of exec_buffer is capped to 256 entries)
|
Not only is exec_buffer using the most cycles but the amount seems to increase…
To instrument it further I added an ad-hoc C interface for using the TSC probes from within the contrib C code - exec_buffer eventually leads to executing lx_drm_ioctl_etnaviv_gem_submit() and that ends in etnaviv_gem_submit(). (The gem_submit object contains a list of all buffer-objects needed to full-fill the request.)
For good measure I decided I will probably get away with 32 probes at most and since it must not be totally accurate opted for realizing each probe as Genode::Constructible
enum { MAX_PROBES = 32 };
static Genode::Log_tsc_probe::Stats *_probe_stats[MAX_PROBES];
static Genode::Constructible<Genode::Log_tsc_probe> _probes[MAX_PROBES];
void *genode_log_tsc_stats(unsigned id, unsigned number)
{
if (id > MAX_PROBES)
return nullptr;
if (!_probe_stats[id])
_probe_stats[id] =
new (Lx_kit::env().heap) Genode::Log_tsc_probe::Stats(number);
return _probe_stats[id];
}
void genode_log_tsc_init(void *p, unsigned id, char const *name)
{
if (!p || id > MAX_PROBES)
return;
Genode::Log_tsc_probe::Stats &stats =
*reinterpret_cast<Genode::Log_tsc_probe::Stats*>(p);
if (!_probes[id].constructed())
_probes[id].construct(stats, name);
}
void genode_log_tsc_destroy(unsigned id)
{
if (id > MAX_PROBES)
return;
_probes[id].destruct();
}
At the beginning of etnaviv_gem_submit() I constructed each stats object once and sprinkled genode_log_tsc_init() as well as genode_log_tsc_destroy() calls around in the function. I loosely followed the flow of the function grouping allocation, copying of user-data, submitting and pinning objects and so on.
Triggering the probes filled the LOG up with the following measurements:
[…] [init -> imx8mq_gpu_drv] TSC alloc: 136961825 240 calls, last 984581 [init -> imx8mq_gpu_drv] TSC copy: 181935620 240 calls, last 11495261 [init -> imx8mq_gpu_drv] TSC create: 278965049 240 calls, last 22080073 [init -> imx8mq_gpu_drv] TSC lookup: 322802915 240 calls, last 32958321 [init -> imx8mq_gpu_drv] TSC pin: 377900474 240 calls, last 44007855 [init -> imx8mq_gpu_drv] TSC reloc: 428208047 240 calls, last 54453683 [init -> imx8mq_gpu_drv] TSC perfmon: 470970433 240 calls, last 65178407 [init -> imx8mq_gpu_drv] TSC cmd: 516873304 240 calls, last 76415750 [init -> imx8mq_gpu_drv] TSC lock: 560583238 240 calls, last 86882152 [init -> imx8mq_gpu_drv] TSC fencesync: 605015355 240 calls, last 97474117 [init -> imx8mq_gpu_drv] TSC push: 666882626 240 calls, last 108793953 [init -> imx8mq_gpu_drv] TSC attachfences: 715342436 240 calls, last 119463703 [init -> imx8mq_gpu_drv] TSC put: 778213576 240 calls, last 131226297 [init -> imx8mq_gpu_drv] TSC free: 831738222 240 calls, last 142051758 [init -> imx8mq_gpu_drv] TSC complete: 880407564 240 calls, last 152755435 […]
A simple AWK script processed the entries and transposed rows into columns:
2 558 10592 21121 31578 42867 61413 71984 83597 94443 104886 116313 126960 138750 149245 163967 3 607 10780 21557 32252 43820 54523 65247 76543 87133 97724 109131 123839 135779 146418 157278 4 859 11051 22566 33227 44275 54890 65613 76871 87364 97955 109379 120201 0 147545 162853 5 984 11495 22080 32958 44007 54453 65178 76415 86882 97474 108793 119463 131226 142051 152755 6 1123 11822 22644 33588 53080 63495 74219 85669 96127 106720 118291 128935 140697 151576 162343 7 1333 11797 22655 33330 44416 54861 65628 76638 87104 97762 109285 120083 131975 142751 153585 […]
and the usual GnuPlot magic produces a nice plot
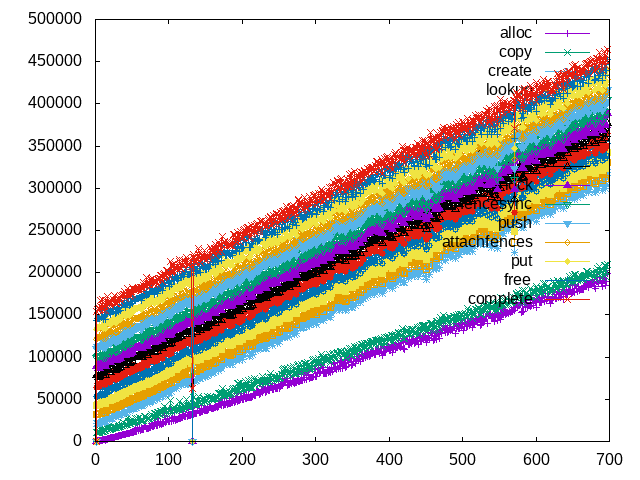
|
|
Another totally scientific plot of cycles spent (y-axis) in different parts of etnaviv_gem_submit
|
All in all the plot shows a slight total increase but which part of the function accounts for most of the increase? Remember when I mentioned explicit allocations a few paragraphs above? Yeah, there a few - and probably a lot more in general - implicit ones in the submit function. For one the ioctl request data is copied from the user-space into the kernel (in our ported driver that resolves to just a mundane memcpy()). To store the copy it allocates dynamic memory. Since I know there is only one client and there is no concurrency in general in this code path the port, turning that into static memory should do no harm. (This is especially true as the memory is freed at the end of the function.)
On the contrary, it seems to make a positive difference:
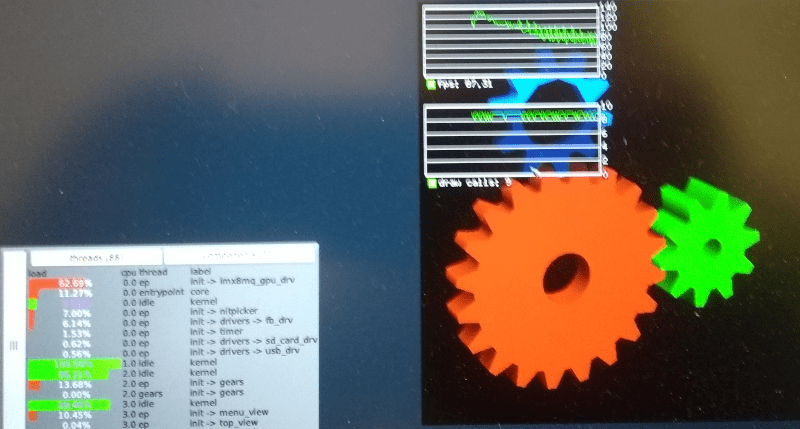
|
|
eglears FPS with replaced dynamic memory for user pages with static memory
|
The TSC probes paint a similar picture where the cycles spent for allocations increase at a more leveled pace. (Since I do not have the plot at hand right now I am going to generously omit it here.)
—
At this point I looked more closely at the memory consumption of the component. After each exec_buffer execution I logged the PD RAM and CAP quota and sure enough it keeps decreasing. That should not happen… so who is not cleaning up properly? (Hint: most of the time it is not the contrib code.)
—
Dummies, dummies, dummies
So, re-occurring dynamic memory allocations lead to decreasing performance. Meh.
As I briefly skimmed over, the Lx_kit::Memory internally uses a registry of the backing memory as well as two maps for access by virtual and physical address (in case of DMA memory). If we somehow leak memory, i.e., miss freeing memory, the registry and the maps could keep on growing. That in return would make look-ups, and to some degree allocations, more costly.
Now, to go back to the beginning of this post, although the new DDE Linux approach relies more on using vanilla sources, there is still the infamous dummies.c file that contains dummy implementations for various functions referenced but not provide by the selected contrib source files. In contrast to the generated_dummies.c file, which is as the name suggests is obtained by automated means, the dummies.c is more of a curated list. Lo and behold, checking it revealed two unimposing functions:
void call_rcu(struct rcu_head * head,rcu_callback_t func) { }
and
void kvfree_call_rcu(struct rcu_head * head,rcu_callback_t func) { }
—
Truth be told, although I had a sinking feeling that I would end up somewhere in this file - especially since I vaguely remembered that the call_rcu() dummy in the previous driver contained a // XXX … comment - I came at it from the other side. I followed the lead from etnaviv_gem_submit() into the DRM subsystem where the DRM scheduler uses some kind of garbage-collection for finished jobs.
—
Should it be as easy as to implement the functions to fix the issue? Embarrassingly enough - yes it is.
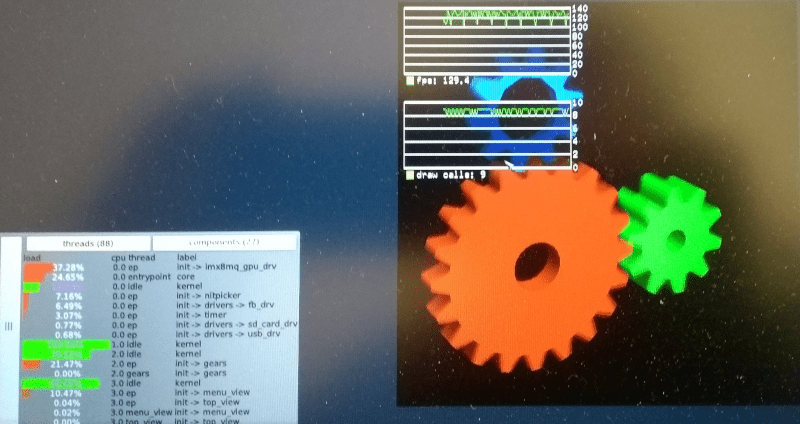
|
|
FPS after plugging the hole
|
Not only did the FPS went up the cycles spend in the driver went down (the load of core is due to the fact I was using the serial connection to dump the probe data - the preferable and less invasive solution would have been to use the TRACE framework).
Take all the caches, leave nothing un-invalidated
We are now up to more reasonable performance, still not good but we will get there. Definitely, maybe. In a previous post I touched upon using cached vs. uncached memory for the buffer-objects. In the end the buffer-object used for as frame-buffer render target (the one where the GPU puts the rendered image that is blitted into the Gui session) was the only one using cached memory. At the time the decision when to use cached memory was made by looking at the size of the buffer and when it reached a given threshold it was assumed it is the frame-buffer. Nothing fancy, slightly error-prone but got the job done for the previous proof-of-concept driver component.
By using the new DDE Linux libraries using cached memory throughout is pretty much a done deal. However, that means the cache has to be maintained for all buffer-objects, i.e. invalidated and cleaned (flushed) for GPU access (reading data prepared by the CPU) and cleaned for CPU access (reading data prepared by the GPU).
(In the lx_emul library there is lx_emul_mem_cache_clean_invalidate() and lx_emul_mem_cache_invalidate(). Both use the corresponding Genode base library functions Genode::cache_clean_invalidate_data() and Genode::cache_invalidate_data(). On base-hw those in return are executing a system-call that deals with each cache-line one 4K page at a time.)
In the current implementation the cache is maintained for each buffer-object referenced by the list in gem_submit. Since the size of a buffer-object ranges from a few KiB to a few MiBs that adds up to a substantial amount of system-calls or rather RPCs from the driver component to core.
The reason for splitting up the cache maintenance operation is because since it is performed by the kernel the time spent for one component should be limited to prevent stalling other components. That being said, maybe we do not need the kernel at all or do we?
On ARMv8 it is possible to let the unprivileged level perform cache maintenance as well. Setting the Sctlr_el1::Uci bit allows for executing the cache clean and invalidate instruction directly in the driver component.
A quick proof-of-concept where the operation is now perform in the driver gave the following result:
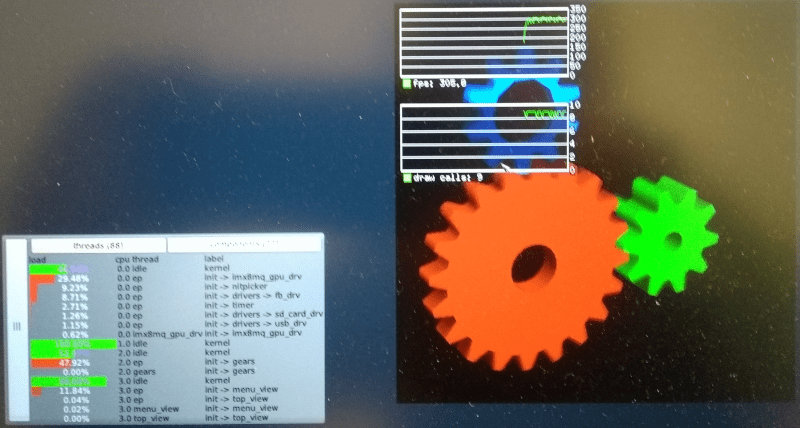
|
|
Cache maintenance in driver component
|
That is a difference indeed.
Conclusion
On the bright side, following the new DDE Linux approach to get the driver up and running was a pleasant experience. This was mostly due to the fact that Stefan and Norman already paved the way by having ported other drivers and so the DDE already covered one or the other subsystem. Nonetheless that hints at spending less time with every new driver where in the past every new driver still involved a measurable amount of effort.
On the not so bright side, some of the encountered obstacles are still homegrown. By pulling in more contrib sources one is confronted to play by the rules more constantly whereas the old DDE Linux was more forgiving when cutting corners^W^Wfinding creative solutions. Well, that is probably a good thing.
Anyway, the GPU driver is now available in the genode-imx repository and its current state is good enough to take a break for now. A recipe for creating a Sculpt pkg that allows for deploying glmark2 directly on your trusted MNT Reform 2 or EVK board is also available in the repository.
For the time being the driver is included in this meta-pkg. This is due to the fact that in contrast to Intel GPU multiplexer the imx8mq_gpu_drv is not part of Sculpt's system image and packaging the driver together with the application circumvents integration work we have not fleshed out yet. It also hints at how the driver is currently supposed to be used: namely there can be only one client at a time.