


Exploring the ARMv8 system level - Virtualization
During last autumn, my colleague Alexander Boettcher and me wrote a virtual-machine-monitor for ARMv8 for Genode from scratch. It was an intensive teamwork and much more fun than just poring alone over some problem. In this fifth post about my ARMv8 first steps, I'd like to summarize some of the insights from this work.
Hardware-assisted virtualization
Most powerful application processors of the ARMv8 universe provide the so called virtualization extensions today. In fact, it is hard to find an ARMv8-a processor without hardware virtualization support. Although, an operating system needs to be aware of it, because it typically starts inside the hypervisor exception level (EL2), there is almost nothing to do in preparation if virtualization is not used. The hypervisor-related system registers that control execution and trap behaviour of the lower exception levels EL0-1 are reset to values that give full access to a kernel running in EL1. In the following, the impact of the virtualization extensions are examined, when actually supporting virtualization as operating system.
The implementation of hardware-assisted virtualization in ARMv8 is quite similar to the ARMv7 virtualization extensions. Of course, the register-set differs that needs to be handled during a world-switch in between different guest operating systems. But the fact that these registers need to be saved and restored manually by the hypervisor remains, and the registers to configure guest access rights are similarly arranged.
We could identify 22 system registers that are reasonable to eagerly handle during a world-switch in the hypervisor, apart from the general-purpose, and FPU registers. Additional registers for debug handling, identification, cache maintenance, and performance measurement can be trapped-and-emulated instead of eagerly switching them. In addition, few registers related to the virtualization support of interrupt controller and generic timer need to be switched too. All in all, the additional complexity to support complete hypervisor functionality in Genode's custom ARM kernel was about 200 lines of C++, and 250 lines of assembler code, thanks to the fact that the hypervisor implementation does not interpret any trap of a virtual-machine (VM) but let the virtual-machine-monitor (VMM) do everything else.
Memory-layout
One limitation in the execution model for EL0-3 in ARMv8 caused us some headache. In EL2 and EL3, there is only one page-table pointer available, whereby in EL0 and EL1 two page-table pointers can span the virtual address space. Typically, the one page-table thereby comprises global kernel mappings, and the second one user-level ones. Thus, there is no need to keep global kernel mappings synchronized in between different page-tables, like in other hardware architectures. But sharing the same address-space layout in between hypervisor and kernel is not possible here. The ARM designers obviously assumed that kernel and hypervisor are always strictly separated concept-wise. Although the limitation of having only one page-table pointer in the hypervisor execution mode was already apparent in ARMv7, it was not a real restriction, because the one page-table could span the whole 32-bit virtual address-space. Therefore, one could re-use the kernel's page-table for the hypervisor by using an appropriated offset for the page-table. In the 64-bit case, this is not possible anymore because the hypervisor's lower page-table has no intersection with the kernel's high page-table, as can be seen in the figure.
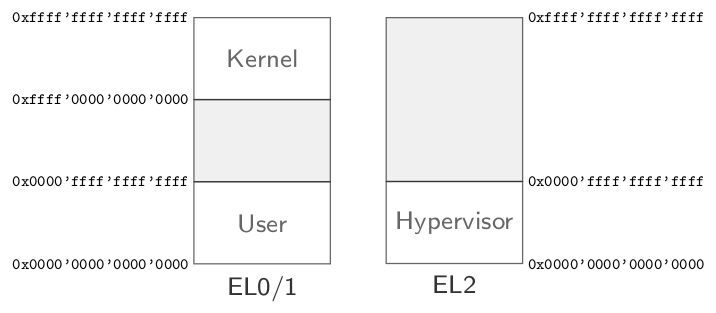
|
|
Memory layout of EL0/1/2
|
In a later revision of the ARMv8 architecture from v8.1, the ability for a second page-table in EL2 got introduced together with additional virtualization host extensions. Nevertheless, the i.MX 8M EVK reference hardware we used, implements v8.0 only.
Due to the fact that the EL2 code in Genode's own ARM kernel is quite limited and provides only one function interface to initiate a world-switch, we could easily cope with the limitation. The solution is again to use the same page-tables in between kernel and hypervisor. But the hypervisor code locates at the bottom, whereby the kernel is located at the top of the address space. The instruction code is compiled as position independent code, and in case of the hypervisor, it is assembler code anyway. Therefore, we have control that no fixed data-addresses are in use. Whenever the hypervisor needs to be invoked by the kernel, the few data-pointers, e.g., the VM state, are handed over by subtracting a fixed offset.
VMM
To actually use the virtualization support, we re-activated the proof-of-concept (PoC) implementation of a former ARM 32-bit virtualization study implemented with the Genode OS framework. The PoC implementation got completed and adapted to match the ARMv8 CPU system registers. On the other hand, device models for timer, RAM, system bus, and UART device could get recycled.
The former interrupt controller model was addressing the GICv2 specification. In the first place, we tried to just re-use that model too. But it turned out that the absence of the legacy mode in the GICv3 implementation of i.MX 8M SoC implies that the hardware-assisted virtualization cannot be used transparently. The model had to be adapted to explicitly provide a GICv3 to the VM. Otherwise, the guest OS would try to access the CPU interface via memory-mapped I/O instead of using system registers, which is not available without legacy mode support even regarding the virtual interface.
Timer
Finally, when using several virtual CPUs in one guest VM an interesting side-effect could be observed with respect to timing.
ARM's generic timer provides a virtual counter that corresponds to the physical counter minus an offset. This offset can be used to measure time when for instance a virtual CPU of a VM was not scheduled. Thereby, a VM does not sense leaps in time. In the first place, our hypervisor measured the counter, whenever a virtual CPU got preempted, and calculated the necessary offset whenever it got scheduled again. Additionally, the VMM added leaps in time to the offset whenever a virtual CPU waited for a interrupts. Although, leaps in time were eliminated by this, and a single-core VM booted fine with linear time, it got stuck when having multi-cores. The reason seems to be cross-CPU synchronization in the Linux guest OS using the virtual counters. Due to different scheduling behaviour for the virtual CPUs, the virtual counters went out of synchronization.
This observation indicates that the virtual counter offset provided by hardware is not helpful in general.