


CPU-load balancing
In the following article the current state of the load balacing topic, as scheduled by the 2020 roadmap, will be described. Additionally, the feature can be test driven by a extended Sculpt 20.08 based image and a video recording is available.
In order to balance load over CPUs, one needs some form of migration support and means to measure the actual load. The ingredients are part of the Genode framework, namely the support to migrate threads via the CPU session, specifying CPU affinities for components and measuring execution & idle times of threads via the Trace session. Up to now, just a recipe were missing combining the ingredients for easier use.
The migration feature got used in the past rarely, respectively is not required nor wanted in static (embedded) scenarios. The reasons are manifold, reaching from who decides when to migrate, which algorithm/policy/schedule to use, performance lost (on non optimal decisions) - in general, to avoid complexity and potentially uncertainty. I tend to share this view.
But as life goes, during the work on Streaming Android to Genode it happened, that I ended up in a situation where I had more (temporarily) very active threads than CPUs available. The jobs of the threads are to decode the received video stream, transforming it to the target resolution, if necessary transform the color depth and push the frames via the GUI session in a timely manner. In the beginning, I tried to monitor, to understand and to manipulate the number of decoding threads manually, to find a somehow working static CPU assignment in order to minimize the dropped frames. Believe me, a very tedious work and effectless, in the general case, at the end.
So the desire, to have an component which does the job arose. A kind of balancer component that monitors the usage pattern of threads and takes migration decisions depending on a configured balancing policy. Such a component should be optional, so that the additional complexity is not needed in general, e.g. for static scenarios.
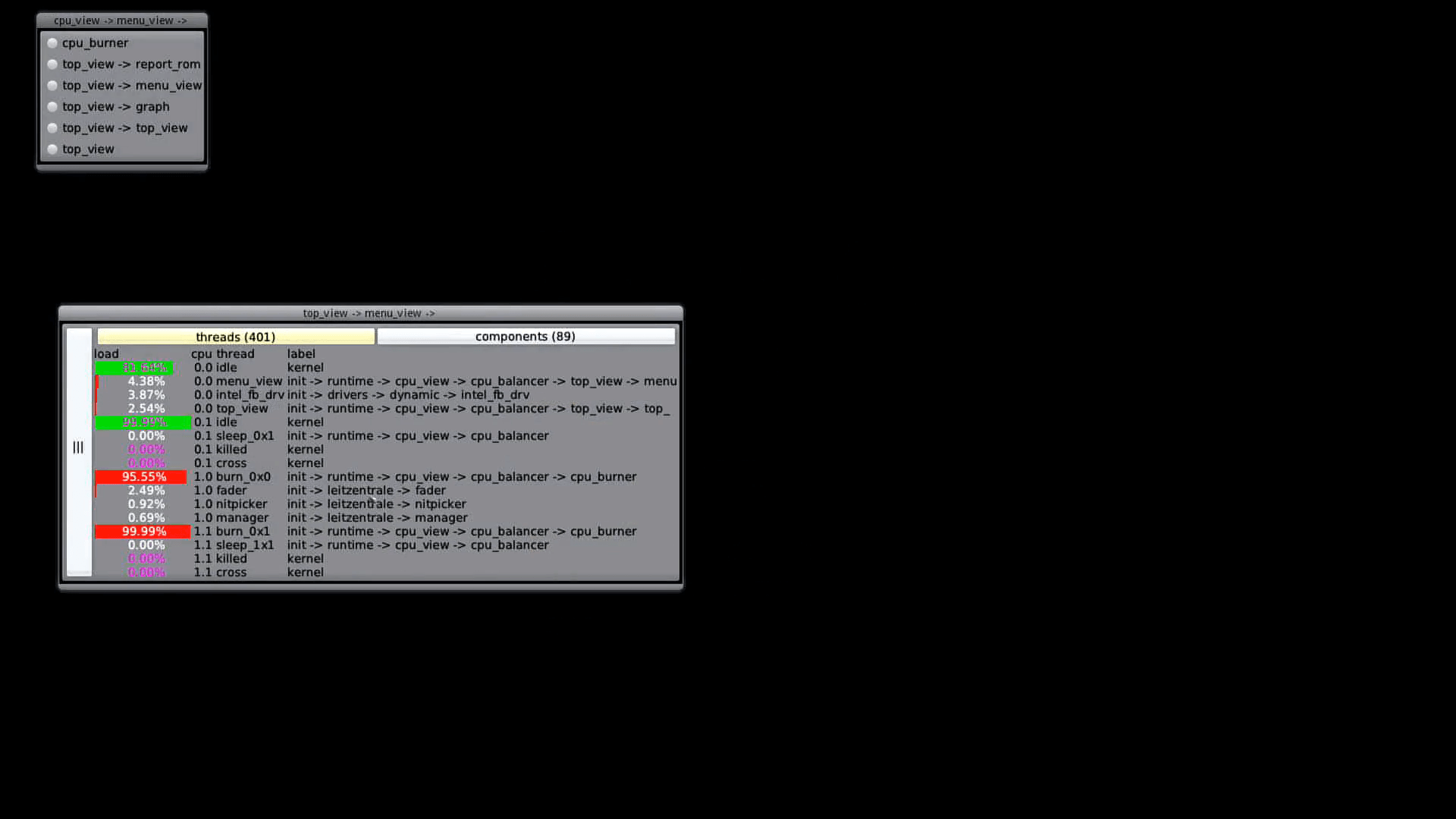
The Genode architecture has the nice aspect, that you can virtualize a session interface by another Genode component, like a proxy. The task of the proxy, called CPU balancer by now, is to monitor the thread lifetime managed via the CPU session. Being the proxy, the CPU balancer gets access to the thread capabilities of connected components, with which it can initiate thread migration. Beside the migration ability, the balancer can use (optional) the Trace session to obtain utilization times for advanced balancer policies. All this should work in principal transparently to the connected components.
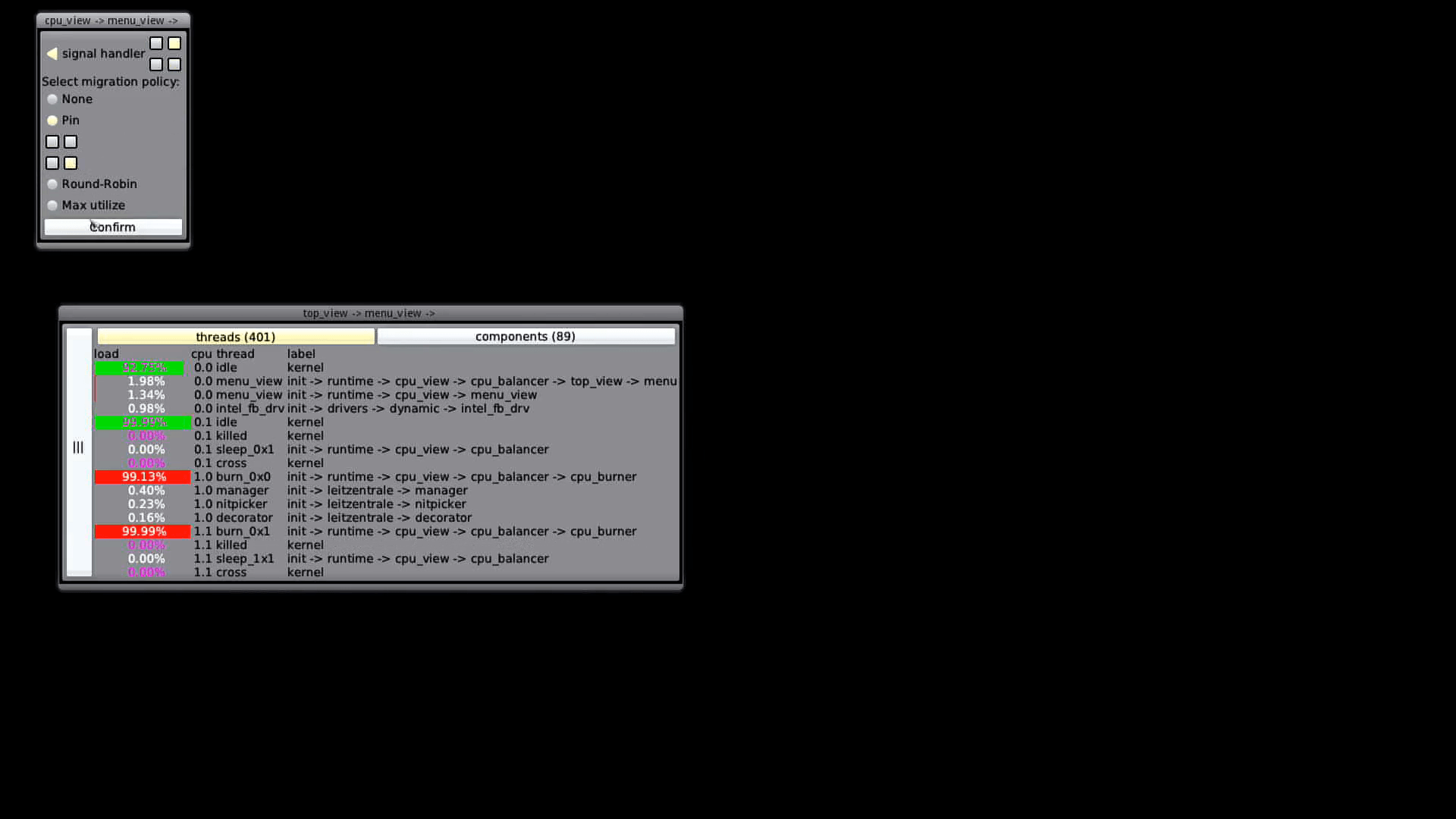
With this idea, over the last months a CPU balancer got developed, first in a very static setup. Simple first balancer policies were to pin (and migrate by need) threads to a specified CPU and to balance/migrate threads in a round-robin fashion. In a second step the utilization data available via the Trace session got added. With this information available, it became possible to add a balancer policy to migrate threads to less utilized CPUs. After the balancer's infancy, it got moved on top of Sculpt which caused its puberty. With the dynamic nature of appearing and disappearing of components on Sculpt the balancer required some internal restructuring in order to cope well with accounting and lifetime of CPU sessions. Additionally, the beforehand hard-coded policies got factored out in separate classes which paves the ground for adding more advanced balancer policies in the future.
Let's have a look on a descriptive example of the balancer and the currently supported policies:
<config prio_levels="2">
<affinity-space width="8" height="2"/>
...
<start name="cpu_balancer">
<config interval_us="10000" report="yes" trace="yes" verbose="no">
<component label="cpu_burner" default_policy="none">
<thread name="signal handler" policy="none"/>
<thread name="burn_0x0" policy="round-robin"/>
<thread name="burn_1x0" policy="max-utilize"/>
<thread name="burn_2x0" policy="pin" xpos="2" ypos="0"/>
</component>
<component label="..." default_policy="max-utilize">
...
</component>
</config>
</start>
<start name="cpu_burner" priority="-1">
<affinity xpos="4" ypos="0" width="4" height="2"/>
<route>
<service name="CPU"> <child name="cpu_balancer"/> </service>
...
</route>
</start>
...
</config>
In the example, the cpu_burner component gets started on a specific restricted affinity space and the CPU session gets established/ proxied via the cpu balancer. The balancer contains a configuration for the cpu_burner, which states that by default the none migration policy is applied for unspecified threads. For specific threads, specific policies are applied. Up to now one can pin a thread to a specific CPU (burn_2x0), schedule the thread round robin within the affinity space of the component (burn_0x0) or try to migrate the thread based on utilization data to maximize utilization (burn_1x0).
For the extended Sculpt 20.08 image, see the beginning of the article, I provide three packages for test driving:
+
-> Depot
-> alex-ab
-> Migration (experimental)
-> cpu_balancer_config (config via recall fs)
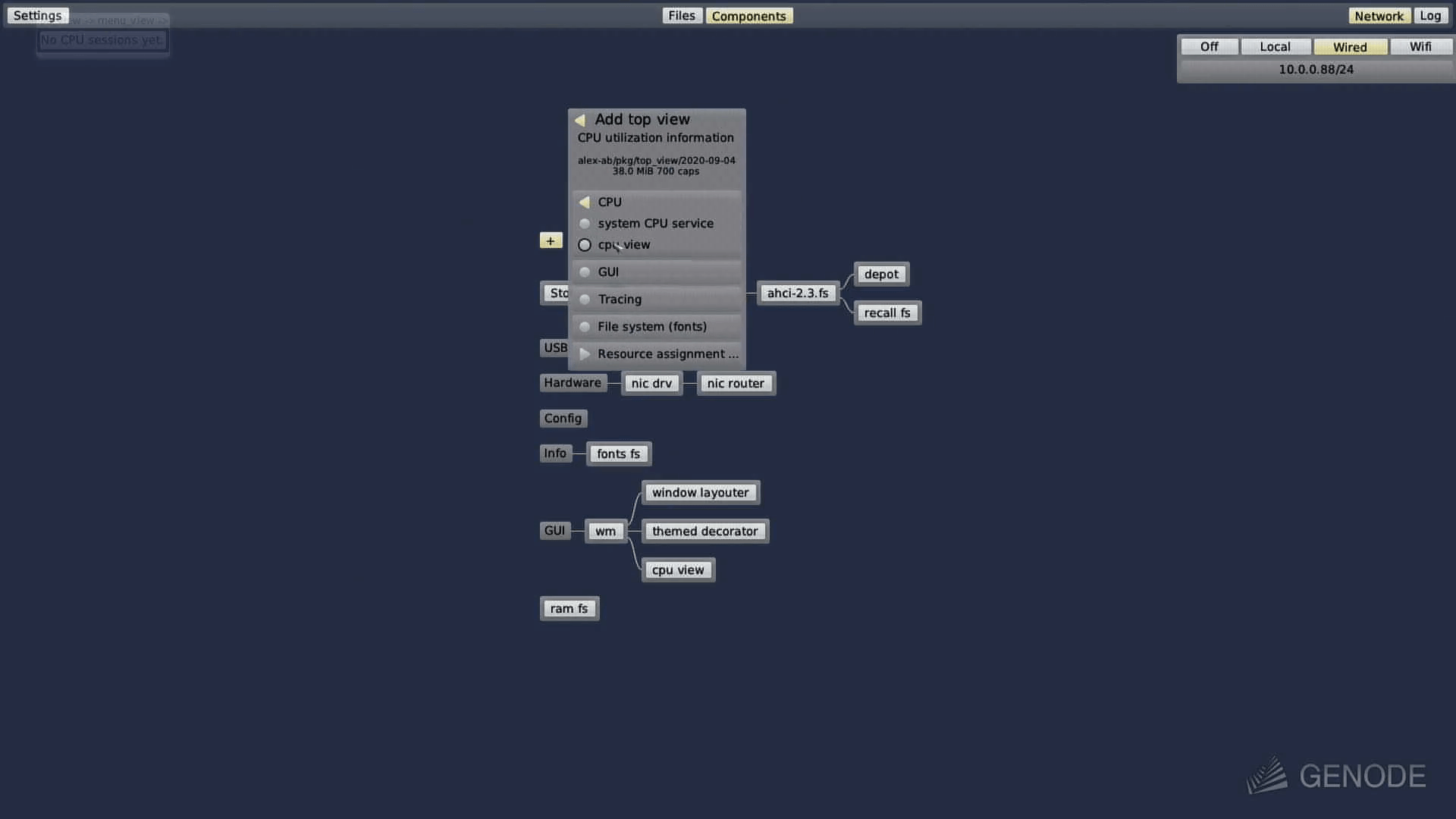
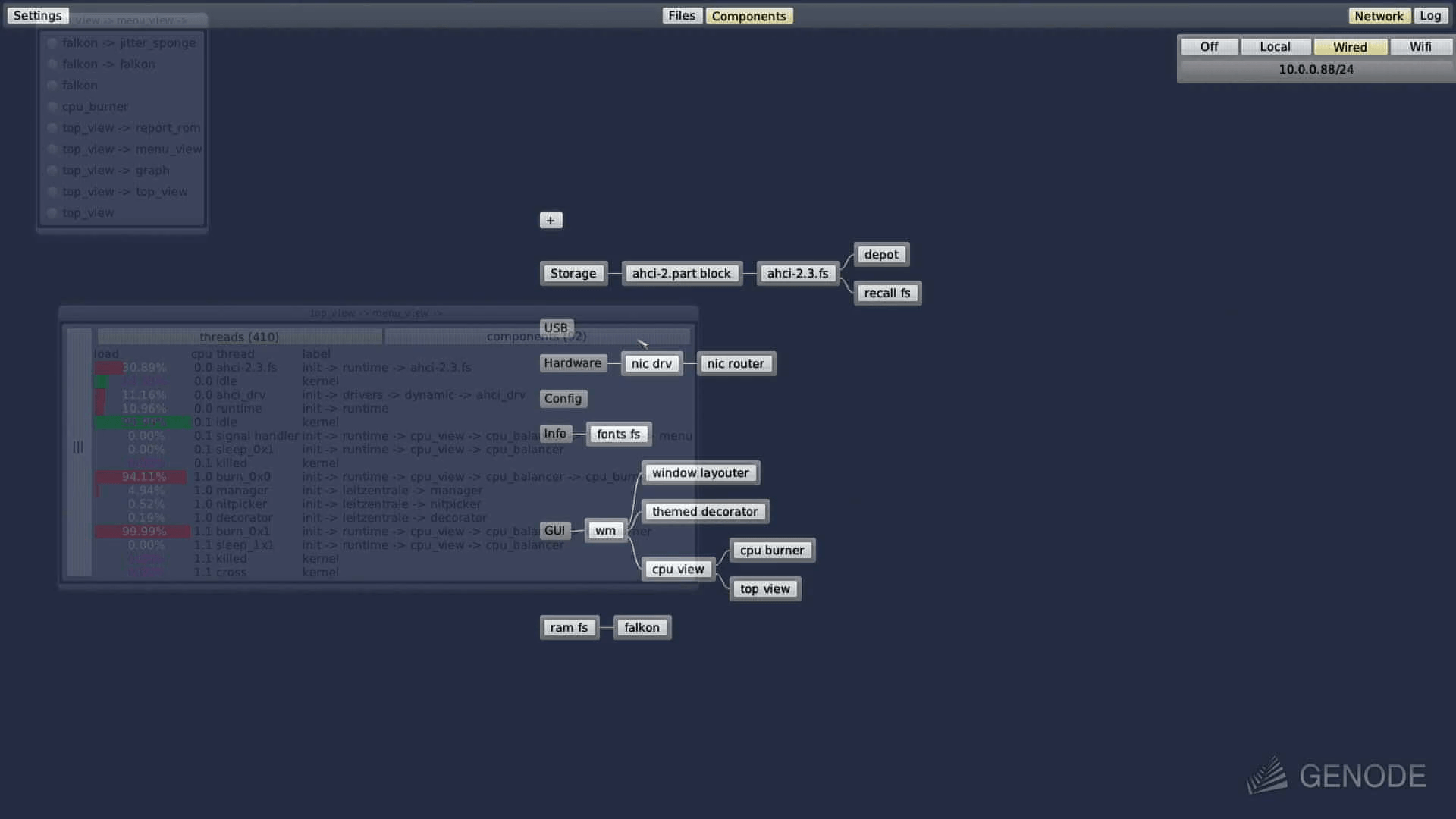
-> cpu_view (GUI + cpu_balancer)
-> cpu_balancer
The cpu_balancer_config package can be used to interactively rewrite the config via the recall filesystem within a shell or inspect window. The cpu_view package is handy if you want to interactively use the mouse to reconfigure CPU balancer policies. As mentioned earlier, the video will give you an first impression to the usage on Sculpt 20.08.
The CPU balancer and the GUI for the balancer on Sculpt in the current form must be considered as highly experimental. The plan is to evolve the functionality and presentation over time with the next Sculpt releases.
|
|
|
|