


Experimental Gpu session for the etnaviv GPU driver
In this series of posts I am going to elaborate on porting the etnaviv driver to Genode and what this effort did entail. The third post is about replacing the ad hoc Drm session with an adapted Gpu session.
Introduction
In the last post we talked about porting the Mesa etnaviv driver to Genode. At the end we left with a working graphics stacks that was able to run glmark2. It, however, used a different session interface than the already available Gpu session. This session was introduced for using Intel GPUs back in 2017 and so is tailored to the needs exposed by the Mesa driver for such devices. The interface differentiates between memory mapped through the global GTT as well as the per-process GTT and allows for setting tiling options on global GTT mapped memory.
With the etnaviv driver there is now a potential second user of the Gpu session at hand that puts the interface to the test.
Detailed look at the Drm session
Before we start replacing the Drm session let us take a closer look at the session itself. This complements the information given in the first part that briefly touched on the driver side of the implementation.
Under the hood the Drm session uses Genode's packet-stream shared-memory abstraction as transport channel between the application and driver component. It is normally used to transfer bulk-data between components and its interface allows for asynchronous operations. Each ioctl request is wrapped into a packet and submitted to the driver component. Most of those packets only contain a few bytes. Others, on the other hand, are bigger and require special treatment because they contain client-local pointers (we will see how we deal with them in a second).
Besides a drm_init() call in the platform-specific EGL code the existence of the session is transparent to the Mesa library. From its point of view requests are still performed via DRM ioctls (recap: for this illusion to uphold we changed the Mesa code to execute the genode_ioctl() instead of the common ioctl() function).
Within this function we adjust the ioctl request as the driver component being a ported Linux driver expects Linux ioctls while our libc is FreeBSD based and, naturally, the internal structure of ioctl differs between both implementations. So, first we translate the request:
int genode_ioctl(int /* fd */, unsigned long request, void *arg)
{
size_t size = IOCPARM_LEN(request);
bool const in = req_in(request);
bool const out = req_out(request);
unsigned long const lx_request = to_linux(request);
Depending on the request we now have to marshal the request's payload. For that we have to know the proper size of the payload data:
/*
* Adjust packet size for flattened arrays.
*/
if (command_number(request) == DRM_ETNAVIV_GEM_SUBMIT) {
drm_etnaviv_gem_submit const *submit =
reinterpret_cast<drm_etnaviv_gem_submit const*>(arg);
size_t const payload_size = Drm::get_payload_size(*submit);
size += payload_size;
} else
[…]
get_payload_size() goes over the request and calculates its proper size. We then allocate a packet to cover the data referenced by the client-local pointers:
Drm::Session::Tx::Source &src = *_drm_session->tx();
Drm::Packet_descriptor p { src.alloc_packet(size), lx_request };
/*
* Copy each array flat to the packet buffer and adjust the
* addresses in the submit object.
*/
if (device_number(request) == DRM_ETNAVIV_GEM_SUBMIT) {
drm_etnaviv_gem_submit *submit =
reinterpret_cast<drm_etnaviv_gem_submit*>(arg);
char *content = src.packet_content(p);
Drm::serialize(submit, content);
} else
[…]
/*
* The remaining ioctls get the memcpy treament. Hopefully there
* are no user pointers left...
*/
if (in) {
Genode::memcpy(src.packet_content(p), arg, size);
}
The serialize function copies the drm_etnaviv_gem_submit object to the front of the packet. A deep copy of each array is append afterwards and the various pointers in the object are replaced with an offset that points into the packet. This offset is later on used by the driver to calculate its own local pointer. This is in contrast to the original implementation where the driver access the user pages directly for its own deep-copy.
The payload is copied into the packet, which we then can submit:
/* * For the moment we perform a "blocking" packet-stream operation * which could be time-consuming but is easier to debug. Eventually * it should be replace by a asynchronous operation. */ src.submit_packet(p); p = src.get_acked_packet();
As already spoiled by the comment above, immediately after submitting the packet we wait for the driver component to process the packet. This will block the client.
if (out && arg) {
/*
* Adjust user pointers back to make the client happy.
*/
if (command_number(request) == command_number(DRM_IOCTL_VERSION)) {
drm_version *version =
reinterpret_cast<drm_version*>(arg);
char *content = src.packet_content(p);
Drm::deserialize(version, content);
} else
[…]
}
src.release_packet(p);
return p.error();
}
Depending on the request we have to prepare the result for consumption by the client.
It is crucial to note that we more or less pass the request from the client to the driver verbatim. Furthermore we do that in synchronous fashion and as a side-effect this has serializing properties. This is useful in case of the WAIT_FENCE or CPU_PREP requests where this behaviour is desired.
Additionally, this makes implementing the driver side more straight forward. It goes without saying that the Drm session does not contain any form of quota management - the driver has to pay for the resource the client wants to consume. A malicious or rather buggy client might bring the driver to its knees
Gpu session to the request, eh?
Inventory of the Gpu session
As mentioned in the introduction there is the Gpu session. Its API solely consists of RPC methods, covering buffer management and execution, complemented by a completion signal for notifying the client. Let us look at each method in more detail:
-
Gpu::Info info() const
This method returns information about the GPU. It also includes the sequence number of the most recently completed execution buffer.
-
Gpu::Info::Execution_buffer_sequence exec_buffer(Genode::Dataspace_capability cap, Genode::size_t size);This method enqueues a execution buffer for execution and returns its corresponding sequence number.
-
void completion_sigh(Genode::Signal_context_capability sigh);
This method establishes the signal handler that is called whenever a execution buffer was executed completely.
-
Genode::Dataspace_capability alloc_buffer(Genode::size_t size);
This method allocates a new buffer.
-
void free_buffer(Genode::Dataspace_capability cap);
This method frees the given buffer and will unmap the buffer if it is still mapped.
-
Genode::Dataspace_capability map_buffer(Genode::Dataspace_capability cap, bool aperture);This method registers the buffer in the global GTT. If instructed by setting aperture to true it tries to map the buffer in the window of the GTT that is also accessible by the CPU through the aperture.
-
void unmap_buffer(Genode::Dataspace_capability cap);
This method removes the mapped buffer from the global GTT.
-
bool map_buffer_ppgtt(Genode::Dataspace_capability cap, Gpu::addr_t va);
This method registers the given buffer in the per-process GTT at the given GPU virtual address.
-
void unmap_buffer_ppgtt(Genode::Dataspace_capability cap, Gpu::addr_t va);
This method removes the mapped buffer from the per-process GTT
-
bool set_tiling(Genode::Dataspace_capability cap, unsigned mode);
This method configures linear access to the given buffer.
As you can see the interface is built around native Genode primitives, namely dataspace capabilities. The identification of buffer-objects by using handles, which is the way of the DRM API, is implemented purely as a client side feature. Each of the DRM API calls is realized as a combination of those RPC calls. When a DRM API call leads to waiting for a certain event, e.g., DRM_I915_GEM_WAIT, the client is put to rest waiting for a completion signal. On its occurrence the client will be woken up and will use the info() method to check if the triggered completion is the one it waited for.
Now RPC methods are neither meant for transferring a large amount of data - depending on the underlying kernel the amount is limited to a few hundred bytes or so - nor for executing long running operations - processing an RPC will prevent the callee from handling other requests generally speaking. In case of our own GPU multiplexer this is not a problem but how well will it work when wrapping the etnaviv driver?
Adapting the Gpu session for etnaviv
As a first step we looked at the driver side of things. There we already employed a Lx::Task for dispatching the various DRM ioctl requests (cf. part 1). The naive approach is wrapping this task dispatching in each of Gpu session's RPC methods.
Let us follow the implementation of alloc_buffer from the driver to the client to get an thorough overview. It starts by implementing the Gpu session interface:
Genode::Dataspace_capability alloc_buffer(Genode::size_t size) override
{
if (_drm_worker_args.request.valid()) {
throw Retry_request();
}
_drm_worker_args.request = Gpu_request {
.op = Gpu_request::Op::NEW,
.op_data = { size, Genode::Dataspace_capability() },
};
_drm_worker.unblock();
Lx::scheduler().schedule();
if (_drm_worker_args.request.result != Gpu_request::Result::SUCCESS) {
throw Gpu::Session::Out_of_ram();
}
Genode::Dataspace_capability cap = _drm_worker_args.request.op_data.buffer_cap;
_drm_worker_args.request.op = Gpu_request::Op::INVALID;
return cap;
}
The _drm_worker_args object contains all arguments that are handed over to the drm-worker task. To keep things simply we only allow for one request to be pending at all times. After setting up the request, the work task gets unblocked and the scheduler is executed immediately. The scheduler will then run all unblocked tasks until no further progress can be made, i.e., all tasks are blocked again. The task's event-loop looks likes this (condensed for brevity):
static void _drm_worker_run(void *p)
{
Drm_worker_args &args = *static_cast<Drm_worker_args*>(p);
while (true) {
/* clear request result */
args.request.result = Gpu_request::Result::ERR;
switch (args.request.op) {
[…]
case Gpu_request::Op::NEW:
{
uint32_t handle;
/* make sure cap is invalid */
args.request.op_data.buffer_cap = Genode::Dataspace_capability();
int err =
lx_drm_ioctl_etnaviv_gem_new(args.drm_session,
args.request.op_data.size, &handle);
if (err) {
break;
}
unsigned long long offset;
err = lx_drm_ioctl_etnaviv_gem_info(args.drm_session, handle, &offset);
if (err) {
lx_drm_ioctl_gem_close(args.drm_session, handle);
break;
}
Genode::Dataspace_capability cap =
genode_lookup_cap(args.drm_session, offset, args.request.op_data.size);
if (!cap.valid()) {
lx_drm_ioctl_gem_close(args.drm_session, handle);
break;
}
args.buffer_handle_registry.insert(handle, cap);
args.request.op_data.buffer_cap = cap;
args.request.result = Gpu_request::Result::SUCCESS;
break;
}
[…]
}
Lx::scheduler().current()->block_and_schedule();
}
}
As you can see here, there are functions that directly wrap a specific DRM API request, e.g., lx_drm_ioctl_etnaviv_gem_new(). Since the kernel references the buffer-objects by handle, we have to build a registry that maps a handle to a capability because our session only deals in capabilities. Eventually we end up with either a valid (the request was successful) or a invalid capability (the request failed). At this point the driver has processed the request. Okay, now what is the client side looking like?
Well, the client initially called DRM_ETNAVIV_GEM_NEW, which is dispatched to the following method:
The method is part of the Drm_call object that encapsulates the 'Gpu::Connection'. This object was instantiated by calling drm_init().
int _drm_etnaviv_gem_new(drm_etnaviv_gem_new &arg)
{
Genode::size_t const size = arg.size;
Genode::Dataspace_capability cap = _alloc_buffer(size);
if (!cap.valid()) {
return -1;
}
Gpu::Handle const handle { _gpu_session->buffer_handle(cap) };
if (!handle.valid()) {
_gpu_session->free_buffer(cap);
return -1;
}
try {
Buffer_handle *buffer =
new (&_heap) Buffer_handle(_buffer_handles, cap,
handle.value, size);
arg.handle = buffer->handle.id().value;
return 0;
} catch (...) {
_gpu_session->free_buffer(cap);
}
return -1;
}
For now we ignore setting errno to an appropriately value…
Here we first try to allocate the buffer. If the attempt is successful, we try to acquire a handle for the capability... wait a minute, this RPC method was not part of the list given in previous section, was it?
Indeed, it was not - this is the first addition to the Gpu session interface done for the etnaviv driver. As mentioned before, the DRM API uses handles to identify buffer-objects and we already deal with them in the driver component.
Since those are used within ioctl requests we have to make sure the driver recognizes them. That leaves us with either keeping track of the handles locally and replacing them with the driver ones whenever we submit the request. However, from the session's point of view, the driver only knows the capabilities and mapping those to the handle is not straight forward because we would have to transfer those capabilities via RPC. That being said, the driver already knows the handle and naturally it knows the capability. That leads to another solution: we ask the driver explicitly for the handle and insert that into the client-local registry. This is where the buffer_handle() method comes into play. For every allocated buffer we lookup the handle chosen by the kernel and return that to the client.
—
As a quick interlude, the _alloc_buffer() method wraps the alloc_buffer() call and takes care of managing the Out_of_ram exception:
Genode::Dataspace_capability _alloc_buffer(Genode::size_t const size)
{
Genode::size_t donate = size;
try {
return Genode::retry<Gpu::Session::Out_of_ram>(
[&] () { return _gpu_session->alloc_buffer(size); },
[&] () {
_gpu_session->upgrade_ram(donate);
donate >>= 2;
}, 8);
} catch (Gpu::Session::Out_of_ram) { }
return Genode::Dataspace_capability();
}
—
This pretty much covers using alloc_buffer() and to some extend buffer_handle() to implement DRM_ETNAVIV_GEM_NEW. The rest of the remaining RPC methods are implemented accordingly. On that account, in case of the port of the etnaviv driver, there is no distinction between memory mapped in the global and per-process GTT and tiling is not set explicitly via the session. Those methods remain not implemented (NOP all the way).
Besides buffer_handle() there is a second addition to the Gpu session interface: wait_fence(). This method is modeled after the ioctl of the same name. Basically you pass in a fence id and check if is marked as finished. In our case that is the sequence number we received when executing exec_buffer(). Whenever DRM_ETNAVIV_WAIT_FENCE is called, we monitor all completion signals and check if by then the fence we wait for has finished.
All in all, the list of RPC methods is extended by
-
Gpu::Handle buffer_handle(Genode::Dataspace_capability cap);
This method returns a handle for the given buffer.
-
bool wait_fence(Genode::uint32_t fence);
This method checks if the given fence is finished.
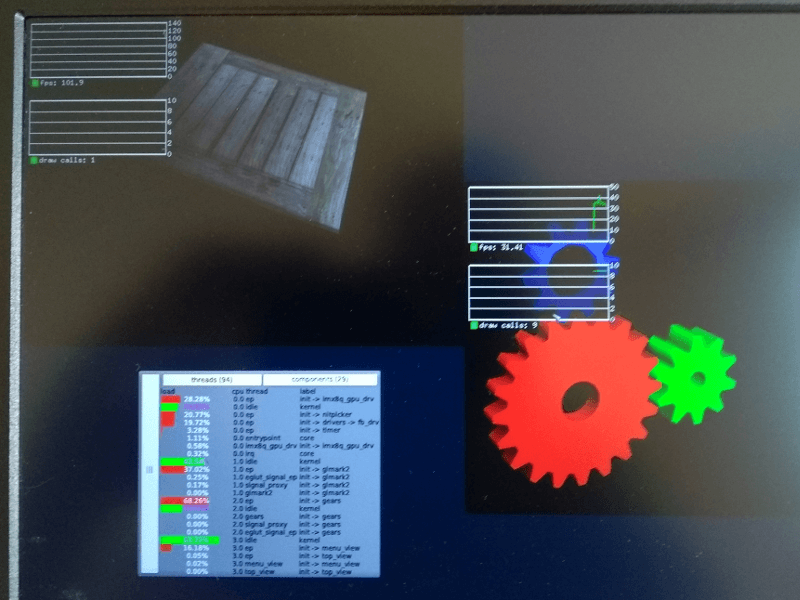
|
|
See glmark2 and eglgears running side-by-side, top view displays the overall load of the system.
|
Summary
With the additions to the Gpu session in place, we have now a functional complete adaptation of the driver. The code and tests run script is available on the topic branch referenced by the 21.08 release notes.
Since we talked about the naive approach a few paragraphs back, one cannot help thinking “we are not there yet, are we?”. For better or worse that is the case indeed.
The way the Gpu session is currently designed does not lend itself well for using it with ported GPU drivers. In this particular situation, the execution flow of the driver component is a problem. With our own GPU multiplexer, which is a single-threaded and (more or less) event-driven state-machine, using an RPC interface is no big deal. All requests are handled in a timely fashion in its entirety. A ported driver, on the other hand, - most of the time - contains multiple threads of execution and requests may be stalled for some amount of time. That is not something the Gpu session was designed for.
With that in mind, the current implementation suffers from a fatal flaw: since a Lx::Task may be blocked for a variety of reasons, like mutex contention, executing the scheduler and calling it a day is not going to work in all cases and merely works by chance. That is exactly an issue we encountered during development. Every now and then Gpu session calls returned with an error while on the driver side everything looked fine. As it turned out, sometimes the ioctl was blocked or rather waiting for some condition to become set. At this point the the drm-worker task was blocked and since no other task was in a runnable state the scheduler returned. However, the initial request was still pending and would eventually handled by the drm-worker task, yikes. One way to cope with such a situation would be defer returning in the RPC and run the scheduler as long as our request has not been finished while still handling signals (to keep the ball rolling). That, however, qualifies more as an band-aid.
Furthermore, in contrast to a ported driver, with our own GPU multiplexer we can properly account for any kind of resource requirements. This is more involving when a driver ported from another OS is at the executing end. It is not that immediately noticeable which side effects an operation might trigger and therefore hard to estimate the amount of RAM or CAPs required beforehand if one tries to employ the usual quota-trading regime. That, however, is a inherent characteristic of a ported driver, which is one of the reasons we try to avoid putting such components in critical roles where the overall liveliness of the system depends on them.
Prospects
The good news is, nothing is set in stone and and we are free to come up with a different design that accommodates the ported-driver use-case in a more matching fashion. And that is exactly what we set out to do by putting the session to the test as mentioned in the beginning of this post.
We already have some appropriate changes in mind and are currently exploring their feasibility. But that is a story for another time…