


Disk I/O optimization with focus on VBox6 - part 1
This first post provides insight into Genode's block I/O stack as used by VBox6 VMs. It starts by recording the status-quo, examining the different layers involved in providing block I/O for VBox6 and shows initial rework steps to improve I/O throughput.
We are spending a substantial amount of time working within the confinements of VMs running on top of Sculpt OS by utilizing our VBox6 port to—amongst other things—develop Genode and Sculpt itself. By now this works reasonable well and we have not paid close attention to specific properties, e.g. the I/O performance, like latency or throughput, in a long time as it appeared to be good enough for our daily workloads. When we were made aware of some unexpected results gathered by running dd and fio in a VM (as the throughput was smaller in comparison to the same test running in VirtualBox on a Linux host), we started to investigate.
In this particular configuration the VM is using a partition on the block device directly as its backing storage rather than a virtual-disk image, i.e. a VDI file. The access is configured via the common “raw-access” using a flat VMDK, through the provided AHCI device-model.
All measurements where performed on the same test-machine, a Fujitsu U7411 with an 11th Gen Intel(R) Core(TM) i7-1185G7 with 32 GiB of RAM and an KIOXIA KBG4AZNS1T02 NVMe SSD. The SSD is connected via PCIe 3.0 x4, while the device places further limits on the used bandwidth.
-
The yellow info sections contain vital information about the performed tests and how they may be interpreted.
-
The blueish observation section outline the results but mostly refrain from interpreting them.
-
Not all tests are alike and comparing them unconditionally is misleading and can be deceiving (e.g. MB/s vs. MiB/s).
-
Idle times show that tests are not CPU-bound on this machine.
-
The generated graph may limit the displayed result range to make differences more apparent. The result table can be consulted in such cases to obtain the plain results.
As first order of business we collected the base-line results for the various tests for the VM use-case ourselves. In particular we followed along the same tests that were initially used but altered them to better match our intend to some degree. We also executed these tests natively on Genode to have something to compare the VM results to - those are expected to be lower due to the overhead induced by the virtualization. On the other hand, shortcomings in the I/O stack are visible with the tests as well. Like VBox6 they also make use of the libc, so changes there should also influence the VM as well.
Initial base-line results
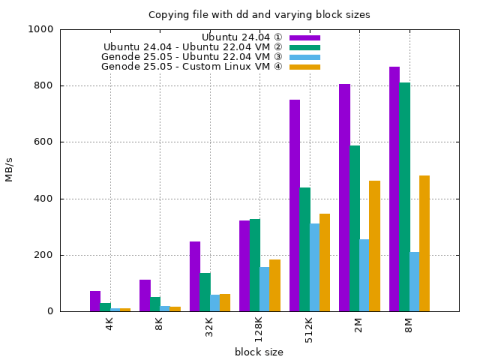
We start with using dd to copy a file block by block with varying block-sizes within a file system and bypassing the OSes block-cache (if available).
① Ubuntu 24.04 natively ② Ubuntu 22.04 in VirtualBox 7.0.x on Ubuntu 24.04 ③ Ubuntu 22.04 in VBox6 on Genode 25.05 ④ Linux OS in VBox6 on Genode 25.05
-
Used command:
dd if=/src.img of=/dst.img bs=<> iflag=direct oflag=direct conv=fsync
-
The same Ubuntu 22.04 VM installation is used in ② and ③.
-
In all VMs the AHCI device-model is selected for the virtual-disk.
-
Virtualbox7 on Linux used the default I/O back-end, host I/O cache or similar options were not enabled/altered.
-
The Linux OS used in ④ consists of a minimal custom OS (see Minimal test VM at the end) that was created to ease further testing after the Ubuntu tests were already performed. In contrast to Ubuntu it uses an Ext2 file system where the former uses Ext4.
|
BS (1) (2) (3) (4) 4K 72.6 29.2 9.4 11.2 8K 112.0 50.2 18.0 15.1 32K 248.0 136.0 57.3 61.8 128K 321.0 326.0 156.0 183.0 512K 751.0 439.0 310.0 345.0 2M 807.0 589.0 255.0 463.0 8M 866.0 811.0 210.0 481.0
-
Throughput with smaller block sizes is severely reduced in the VM.
-
Throughput with larger block sizes exhibits lesser reduction in the VM.
-
Throughput is approximately halved with smaller block sizes when running the test in the Ubuntu 22.04 VM on Ubuntu 24.04 compared to native.
-
Throughput when running the Ubuntu 22.04 VM on Genode is even more reduced
-
Throughput when running the custom Linux VM on Genode is less reduced, especially with larger block sizes.
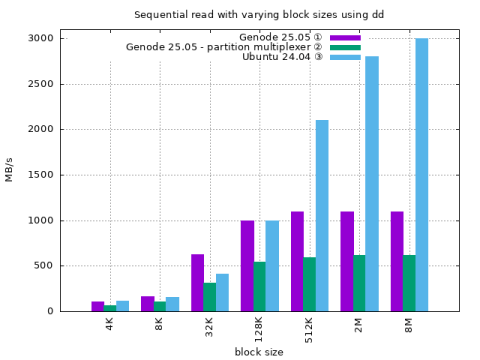
Next are the results for for running dd natively on Genode and for comparison Ubuntu 24.04.
① Genode 25.05 ② Genode 25.05 with partition multiplexer ③ Ubuntu 24.04
-
Used command on Genode 25.05:
dd if=/dev/block of=/dev/null
-
Used command on Ubuntu 24.04:
dd if=/dev/nvme0n1p8 of=/dev/null iflag=direct
-
All components are running on CPU core 0.
-
As the block-device/partition is used directly and Genode does not make use of a block-cache the other flags are omitted.
-
We choose this approach as it mirrors the way a VBox6 VM interacts with Genode when using “raw access” more closely.
-
In contrast to the previous tests these native tests are read-only, so only a one-way I/O operation is performed. The direct variant uses the block-device directly while the part_block variant uses a partition multiplexer in between to access a particular partition on the block-device.
-
The throughput is taken directly from dd log output and is given in MB/s.
-
① Reads from the beginning of the block-device, ② uses a partition at the end.
|
(1) (2) (3)
BS BW (idle %) BW (idle %) BW
4K 105.0 (47.17) 67.8 (51.06) 115.0
8K 167.0 (73.63) 105.0 (60.64) 156.0
32K 626.0 (45.07) 311.0 (54.43) 414.0
128K 1000.0 (59.01) 547.0 (68.85) 1000.0
512K 1100.0 (73.70) 596.0 (65.31) 2100.0
2M 1100.0 (65.92) 619.0 (65.15) 2800.0
8M 1100.0 (67.53) 620.0 (65.25) 3000.0
-
Throughput on Genode 25.05 is similar to Ubuntu 24.04.
-
Throughput on Genode 25.05 is capped when using larger block sizes.
-
Throughput on Genode 25.05 when using the partition manager is almost halved.
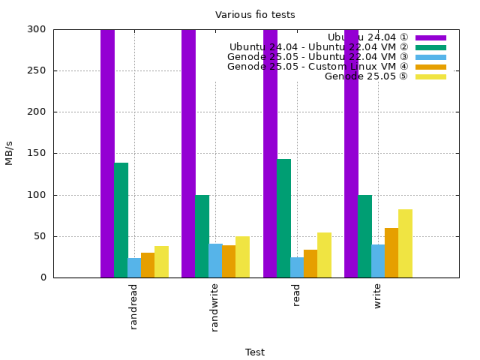
In addition to dd we also gave the commonly used fio tool a spin. We performed similar tests to dd but also made use of a deeper I/O queue.
For that first we had to port fio to Genode, which we made with the help of goa, as it was not yet readily available.
① Ubuntu 24.04 natively ② Ubuntu 22.04 in Virtualbox 7.0.x on Ubuntu 24.04 ③ Ubuntu 22.04 in VBox6 on Genode 25.05 ④ Custom Linux in VBox6 on Genode 25.05 ⑤ Genode 25.05 natively
-
Used command for Linux:
rw=randread bs=4k ioengine=libaio iodepth=64 direct=1 buffered=0 runtime=20 time_based rw=randwrite bs=4k ioengine=libaio iodepth=64 direct=1 buffered=0 runtime=20 time_based rw=read bs=4k ioengine=libaio iodepth=64 direct=1 buffered=0 runtime=20 time_based rw=write bs=4k ioengine=libaio iodepth=64 direct=1 buffered=0 runtime=20 time_based
-
Used command for Genode 25.05:
rw=randread bs=4k ioengine=sync iodepth=64 direct=1 buffered=0 runtime=20 time_based rw=randwrite bs=4k ioengine=sync iodepth=64 direct=1 buffered=0 runtime=20 time_based rw=read bs=4k ioengine=sync iodepth=64 direct=1 buffered=0 runtime=20 time_based rw=write bs=4k ioengine=sync iodepth=64 direct=1 buffered=0 runtime=20 time_based
-
The I/O stack components like driver and partition multiplexer run on CPU 0, while the VM uses disjunct CPU cores.
-
On the native as well as the virtualized Linux OSes the libaio back-end of fio is used.
-
On Genode the sync back-end is configured, which also restricts the I/O queue depth to 1, and the partition multiplexer used (write request are confined).
-
On Genode /dev/block is used directly, like in the dd tests no file system is involved.
|
(1) [sync] (2) (3) (4) (5)
randread 1391.0 (64.7) 139.0 23.9 29.5 37.8
randwrite 761.0 (282.0) 99.9 40.4 38.8 50.2
read 1065.0 (65.3) 143.0 24.5 33.9 54.3
write 688.0 (292.0) 99.7 39.9 59.4 82.5
-
Throughput on native Linux is a magnitude higher.
-
Throughput favors reads on Linux while the opposite is true for Genode where writes are favored.
-
Throughput in the VM is much lower.
Block I/O layers
With these initial results obtained let's briefly examine the role of each of the layers involved when doing I/O.
As mentioned VBox6 relies on the usual libc facilities to perform I/O operations and thus we have to make Genode's own Block session available in this environment. For this purpose there exists the VFS Block plugin that converts Block session operations into VFS operations that in return are mapped to the common POSIX file I/O operations within our libc.
The layering is as follows:
❶ The block-device driver (for the test-machine this is driver/nvme) makes access to the device available via Genode's Block session and implements the https://genode.org/documentation/genode-foundations/25.05/api/OS-level_session_interfaces.html#Server-side_block-request_stream - Block::Request_stream API]. The driver is only accessed by one user at a time.
❶ The part_block resource multiplexer makes each partition on a block-device available as a disjunct Block session. It also implements the Block::Request_stream API but at the same time is itself a user of the driver and has one connection to it. Each provided Block session by part_block isolated from the other ones and is only accessed by one user at a time.
❸ The VFS Block plugin converts the Block session into VFS I/O operations and vice versa. Whenever one wants to access a Block session from Genode's VFS one has to go through that plugin.
❹ The libc provides the common POSIX file I/O facilities and wraps Genode's VFS. A read(2) or write(2) call to will go through that VFS mechanism and thereby the plugin.
❺ The component using the libc—VBox6, dd or fio—will call the adequate I/O function.
Each layer can influence how I/O is performed by adjusting or rather choosing different parameters, like buffer-size and the number or nature of batched operations.
The driver and the partition multiplexer are separate components while the VFS plugin and libc are part of the component using them.
Looking at the layers with preknowledge, we omit ❶, ❹ and ❺ for now. The driver was found performing adequately in earlier tests and the I/O path in the libc does not raise immediate concern. The component using the libc, on the other hand, presumably uses the I/O API in a reasonable way.
VFS Block plugin renovation
We start with ❸ - the VFS Block plugin. In its current incarnation it hails back from the olden days where it started its life in noux, our unix-runtime-server that by now is already long in retirement. Renovating the plugin paves the way for putting us in a position where we can more easily make adjustments for optimizations and potentially add features in the future that were not possible before.
I/O buffer size change
The first change is increasing the shared-memory that is used for transferring data between the block-provider (part_block) and the client (VBox6 or other components running on top of the VFS). The current size of the shared-memory buffer is hard-coded to 128 KiB, which is more on the conservative side of things. The new default is 4 MiB and the block_buffer_count configuration attribute, which previously was used to size an aggregation buffer— most of the time it is set to 128 which results in 64 KiB with 512b sector sizes —, is replaced with the io_buffer attribute that sizes the shared-memory as well.
This change results in better utilization when larger I/O operations are performed. As more data fits the buffer now, we can make due with less round-trips.
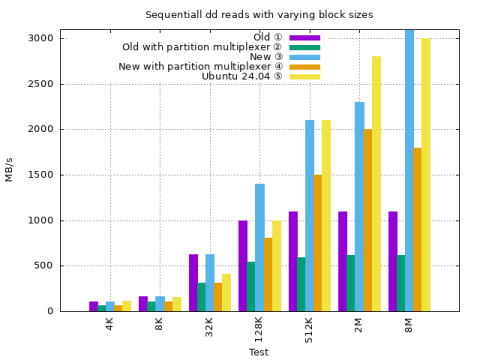
dd natively on Genode with I/O buffer size adjustments
① VFS Block plugin ② VFS Block plugin and partition multiplexer ③ VFS Block plugin with io_buffer ④ VFS Block plugin with io_buffer and partition multiplexer ⑤ Ubuntu 24.05
-
The tests use the same parameters as the dd run in the initial base-line section.
|
(1) (2) (3) (4) (5)
BS BW (idle %) BW (idle %) BW (idle %) BW (idle %) BW
4K 105.0 (47.17) 67.8 (51.06) 105.0 (47.72) 67.8 (50.82) 115.0
8K 167.0 (73.63) 105.0 (60.64) 166.0 (73.72) 105.0 (60.55) 156.0
32K 626.0 (45.07) 311.0 (54.43) 625.0 (45.08) 310.0 (54.34) 414.0
128K 1000.0 (59.01) 547.0 (68.85) 1400.0 (70.16) 806.0 (75.32) 1000.0
512K 1100.0 (73.70) 596.0 (65.31) 2100.0 (77.82) 1500.0 (73.44) 2100.0
2M 1100.0 (65.92) 619.0 (65.15) 2300.0 (78.06) 2000.0 (72.74) 2800.0
8M 1100.0 (67.53) 620.0 (65.25) 4200.0 (74.87) 1800.0 (62.55) 3000.0
-
Throughput with the default io_buffer size of 4 MiB lifted the form cap with larger block sizes.
-
Throughput with a block size of 8M on Genode is faster suspiciously faster than on Ubuntu.
-
Throughput now generally in the same ballpark as Ubuntu.
-
Throughput with partition multiplexer regresses with 8M block size.
Job API
The next change is getting rid of the direct usage of the Block::Connection. Instead we make use of Block Job API as a convenience utility that deals with some of the corner-cases of our Packet-stream API and also handles oversized requests that do not fit the shared-memory gracefully by splitting them up in manageable portions.
Using this API makes it more straightforward to handle unaligned and partial requests where the offset and amount of data not matches the underlying block session properties. The old code was error-prone and already did hide bugs in plain sight.
Since the job API already uses a queue mechanism internally, we are free to issue multiple requests. This might come in handy when using multiple VFS handles to issue multiple requests concurrently.
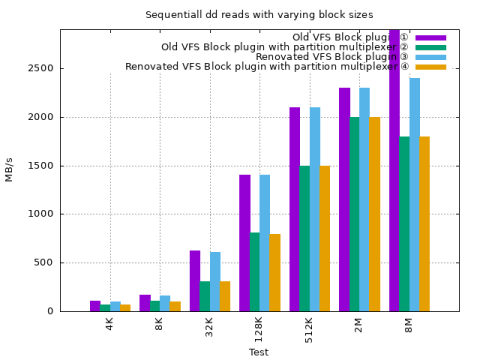
dd natively on Genode with renovated VFS Block plugin
① Old VFS Block plugin ② Old VFS Block plugin with partition multiplexer ③ Renovated VFS Block plugin ④ Renovated VFS Block plugin with partition multiplexer
-
The tests use the same parameters as the dd run in the initial base-line section.
|
(1) (2) (3) (4)
BS BW (idle %) BW (idle %) BW (idle %) BW (idle %)
4K 105.0 (47.72) 67.8 (50.82) 100.0 (49.95) 66.0 (49.37)
8K 166.0 (73.72) 105.0 (60.55) 160.0 (57.35) 103.0 (59.43)
32K 625.0 (45.08) 310.0 (54.34) 608.0 (42.87) 306.0 (52.96)
128K 1400.0 (70.16) 806.0 (75.32) 1400.0 (60.03) 797.0 (67.82)
512K 2100.0 (77.82) 1500.0 (73.44) 2100.0 (76.69) 1500.0 (69.60)
2M 2300.0 (78.06) 2000.0 (72.74) 2300.0 (68.67) 2000.0 (69.00)
8M 4200.0 (74.87) 1800.0 (62.55) 2400.0 (70.47) 1800.0 (63.19)
-
Throughput with the renovated plugin is similar to the old one.
-
Throughput with a block size of 8M is now more in line.
partition multiplexer as mediator
Next we deal with ② - the block partition multiplexer.
When paying attention to the CPU load during the test execution it becomes apparent that a measurable amount, depending on the test and used test-machine up to 20% total execution time, of CPU cycles are spent in part_block. As part_block is the Block session multiplexer that allows multiple clients to access different partitions on the same block-device concurrently it makes a copy of every block it receives from its block-provider. It has one connection to the driver that is used for data transfer.
In the test-results shown above that does not make much of a difference, as there is still idle time left but it could make all the difference when the system is under load.
By turning the part_block component in a mediator that merely arranges which component may access the specific range of blocks covering a given partition on the one hand-side we could economize CPU cycles. On the other hand-side would could potentially also make better use of available hardware resource because now the client component has a more direct access to the device and any I/O buffer can be sizes in a more optimal way.
A down-side of this approach is that the driver now has to accommodate multiple clients, which increases its complexity and might require some kind of I/O scheduling on its side.
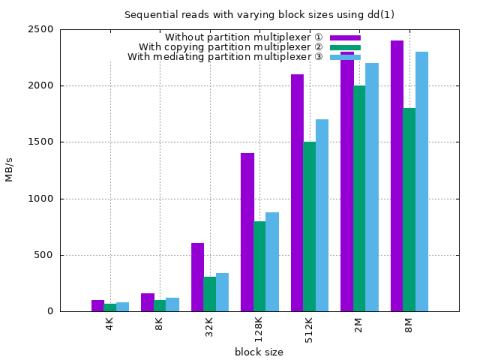
dd natively on Genode with renovated VFS Block plugin and partition mediator
① Without partition multiplexer ② With copying partition multiplexer ② With mediating partition multiplexer
-
The tests use the same parameters as the dd run in the initial base-line section.
|
(1) (2) (3)
BS BW (idle %) BW (idle %) BW (idle %)
4K 100.0 (49.95) 66.0 (49.37) 78.3 (58.94)
8K 160.0 (57.35) 103.0 (59.43) 118.0 (68.02)
32K 608.0 (42.87) 306.0 (52.96) 341.0 (62.31)
128K 1400.0 (60.03) 797.0 (67.82) 875.0 (82.13)
512K 2100.0 (76.69) 1500.0 (69.60) 1700.0 (73.29)
2M 2300.0 (68.67) 2000.0 (69.00) 2200.0 (71.82)
8M 2400.0 (70.47) 1800.0 (63.19) 2300.0 (81.22)
-
Throughput with the mediating partition multiplexer is higher.
-
Idle time with the mediating partition multiplexer is higher.
-
Throughput with the mediating partition multiplexer is still substantially slower than using the block device directly.
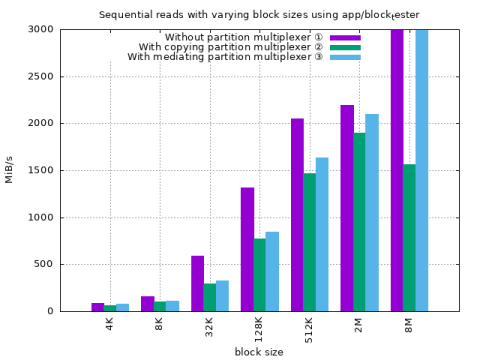
Genode's block_tester component with partition mediator
There is app/block_tester, a component that is loosely comparable to fio and that exists to allow for a similar type of testing. In contrast to dd and fio it uses the Block session directly and does not rely on a libc.
① Without partition multiplexer ② With copying partition multiplexer ② With mediating partition multiplexer
|
(1) (2) (3)
BS BW (idle %) BW (idle %) BW (idle %)
4K 90.74 (47.95) 64.92 (51.36) 76.80 (60.82)
8K 156.31 (73.65) 100.60 (60.87) 114.51 (69.57)
32K 593.79 (44.23) 297.92 (64.36) 331.06 (77.99)
128K 1314.75 (69.03) 770.99 (74.55) 844.60 (80.68)
512K 2049.36 (76.97) 1465.22 (73.26) 1633.60 (81.15)
2M 2190.84 (78.03) 1901.22 (72.26) 2094.49 (77.09)
8M 4447.91 (64.14) 1562.16 (55.86) 4300.71 (62.54)
-
Throughput is in the same ballpark park with dd.
-
Throughput with 8M block size looks suspicious.
Asynchronous I/O
In the beginning we mentioned that fio on Linux uses the libaio back-end that amongst other things, allows for a deeper I/O queue. Since our libc is FreeBSD-based, we do not have access to Linux libaio (or rather conventional programs would not expect having that) but the POSIX AIO API is there.
Now, the POSIX AIO API is apparently not the nicest interface out there but nonetheless allows for issuing multiple I/O operations in a batch.
We implemented the aio(4) functions used by fio's posixaio ioengine whose implementation we had to adapt slightly to account for the difference in POSIX AIO implementations when it comes to error propagation (error as result value vs. error via errno).
Since this is a first attempt we kept the implementation itself rudimentary in nature. Under the hood we allow for at most 64 requests on a given file descriptor and handle the pending requests each by each for each file descriptor sequentially before enqueuing new requests.
fio submits each request asynchronously by enqueuing it with aio_read or aio_write until the submit is denied and waits for the completion by executing aio_suspend with the list of currently outstanding requests.
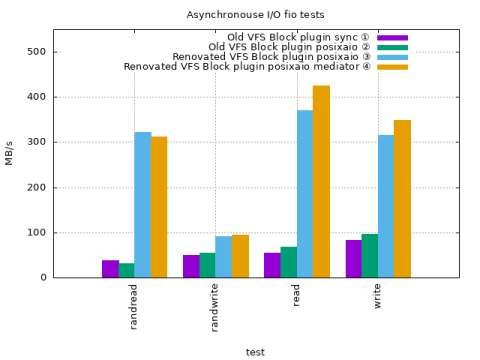
① Old VFS Block plugin fio sync ioengine and copying partition multiplexer ② Old VFS Block plugin fio posixaio ioengine and copying partition multiplexer ③ New VFS Block plugin fio posixaio ioengine and copying partition multiplexer ④ New VFS Block plugin fio posixaio ioengine and mediating partition multiplexer
-
The tests use the same parameters as the fio run in the initial base-line section.
|
(1) (2) (3) (4)
test BW (idle 0, 2 %) BW (idle 0, 2 %) BW (idle 0, 2 %) BW (idle 0, 2 %)
randread 37.8 (72.22, 86.24) 30.8 (80.54, 95.43) 322.0 (37.07, 78.20) 312.0 (56.90, 72.56)
randwrite 50.2 (65.84, 88.21) 54.7 (67.45, 93.42) 91.3 (82.91, 93.73) 93.9 (86.58, 94.09)
read 54.3 (60.87, 80.98) 67.4 (59.19, 93.15) 371.0 (37.96, 76.30) 426.0 (45.85, 69.11)
write 82.5 (43.88, 80.46) 96.5 (42.19, 88.23) 315.0 (43.29, 79.26) 349.0 (52.02, 78.87)
-
Throughput with the old VFS Block plugin is slightly better when using posixaio
-
Throughput with the new VFS Block plugin is much higher when using posixaio and profits from the mediating partition multiplexer also.
VBox6 POSIX AIO
While instrumenting the nature of the I/O requests when running the dd and fio tests in the small test VM we noticed that especially the larger requests are chopped into multiple smaller ones. If we somehow could make use of that fact we might be able to decrease the overhead of issuing them one by one. Some kind of batching might do the trick and could also turnout to be useful during regular I/O operations in the VM.
VBox6 supports batching when using its asynchronous I/O facility. This is normally used when its internal I/O manager or the specific option UseNewIo is enabled. The asynchronous I/O mechanism naturally has multiple back-end implementation for the various host OSes that Virtualbox supports. A generic POSIX AIO and FreeBSD specific (that uses kqueue as notification mechanism) back-end are available.
We went for the generic one as its compilation unit is already part of our VBox6 port and its usage pattern is similar to fio. Rather than enqueuing the requests one by one it prepares a batch (containing one or more requests) of requests submits them via lio_listio.
Whenever the guest OS issues a I/O request it will go through a bunch of layers. It first hits the AHCI device-model (DevAHCI) via MMIO where the guest places one or more requests in a command slot. The device-model then calls the virtual-disk driver (DrvVD), which calls the VMDK driver (VMDK). This, on the other hand, calls DrvVD again and ends up calling the virtual-disk I/O interface (VD).
When synchronous I/O is performed, it makes a call to RTFileReadAt or RTFileWriteAt that in return will call a combination of lseek(2) and read(2)'/'write(2). As this call is handled directly, the initial AHCI command slot submit function returns with “transfer complete”. As VBox6 spawns a thread per AHCI port this synchronous operation does not block the overall processing in the VMM.
On the other hand, when asynchronous I/O is performed, requests will be submitted without being processed immediately. In addition to the port thread, there is another AioMgr thread that orchestrates all asynchronous I/O operations. With more threads involved in doing I/O more overhead might occur.
For testing purposes we forced the usage of the asynchronous I/O back-end by unconditionally setting the UseNewIo flag.
Minimal test VM dd with partition mediator
① Old VFS Block Plugin with copying partition multiplexer ② New VFS Block Plugin with copying partition multiplexer ② New VFS Block Plugin with mediating partition multiplexer ② New VFS Block Plugin with mediating partition multiplexer and asynchronous I/O
-
The tests use the same parameters as the dd VM runs in the initial base-line section.
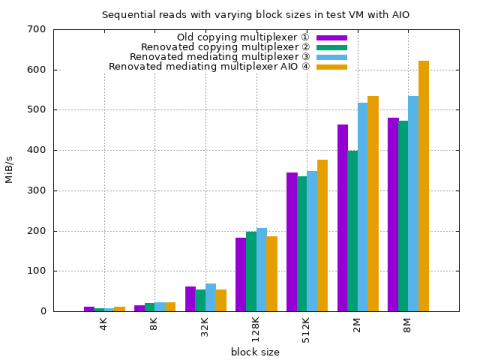
|
(1) (2) (3) (4)
BS BW BW BW BW
4K 11.2 7.8 8.1 11.6
8K 15.1 21.2 22.9 22.9
32K 61.8 53.4 68.7 53.8
128K 183.0 198.0 207.0 187.0
512K 345.0 335.0 349.0 376.0
2M 463.0 398.0 518.0 534.0
8M 481.0 472.0 534.0 622.0
-
Throughput with the new VFS Block plugin slightly decreased.
-
Throughput with the mediating partition multiplexer increased.
-
Throughput using larger block sizes were further increase when enabling asynchronous I/O.
Minimal test VM fio with partition mediator
① Old VFS Block Plugin with copying partition multiplexer ② New VFS Block Plugin with copying partition multiplexer ② New VFS Block Plugin with mediating partition multiplexer ② New VFS Block Plugin with mediating partition multiplexer and asychronous I/O
-
The tests use the same parameters as the fio VM runs in the initial base-line section.
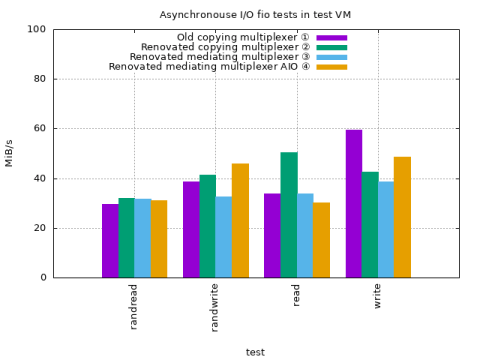
|
BW (idle core 0, 1, 2)
test (1) (2) (3) (4)
randread 29.5 (72.48, 7.87, 54.60) 31.9 (72.03, 3.63, 75.62) 31.7 (81.36, 9.10, 53.67) 31.1 (82.97, 6.84, 67.78)
randwrite 38.8 (64.69, 2.34, 96.08) 41.4 (62.91, 7.51, 13.56) 32.5 (80.78, 15.42, 26.73) 45.8 (81.21, <5.9, 95.68)
read 33.9 (72.45, 5.27, 91.10) 50.5 (74.14, 10.14, 54.79) 33.9 (82.42, 2.46, 88.70) 30.1 (83.52, <3.0, 86.82)
write 59.4 (55.66, 11.11, 24.38) 42.6 (63.39, 10.27, 17.56) 38.6 (78.98, 13.23, 22.48) 48.5 (78.70, 7.36, 71.13)
-
Throughput with the renovated VFS Block plugin is slightly better overall with the copying partition multiplexer.
-
Throughput with the renovated VFS Block plugin and the mediating partition multiplexer is low but CPU idle time is higher on core 0.
Interim conclusion
At first glance the current results may appear bleak. Increasing the I/O buffer size and thus the bandwidth made the biggest impact when it comes to throughput yet. Renovating the VFS Block plugin for the moment only provides a benefit when asychronous I/O operations are in play. The mediating partition multiplexer allows for more throughput and lessens the CPU load but in a smaller range then expected. In its current implementation it should not have any effect after the Block session has been established and the throughput should be the same as when it is not used.
On the second glance we are now in a better position. Having done the groundwork for the testing infrastructure—in Genode speak that means having created multiple run-scripts and modular Sculpt OS configurations that allow for effortless automated testing—as well as cleanup of vital components that will aid us in further endeavors (more flexible VFS Block plugin and multi-queue support in the NVMe driver, which could come in handy when concurrently using mutliple VMs).
Next steps
The current tests focused on throughput but latency is also relevant when multiple components are involved. So allowing for the batching of requests nonetheless seems worthwhile although the first experiments with VBox6 are stuttering.
That being said, we briefly looked at the potential overhead introduced by the libc when also executing our block_tester component. Switching to the other VMM available on Genode—Seoul—could also provide some worthwhile insight as it does not rely on a libc, is not as multi-threaded in its implementation and its Genode service bindings are more direct. Insights gained here could be transfered back and applied to the VBox6/libc combination.
So far we have taken the testing programs and the guest OS mostly as-is. Reasons for employing a custom Linux system were for one having more control over the system and on the other hand keeping the variance down by severely limiting the running processes. But we can go one step further by using a Genode guest where we can mandate the I/O operations down to each single request.
All in all, there is still enough ground available to cover on the what and how to test. We will deal with that in part 2 of this series.
Minimal test VM
As hinted in the Initial base-line results we created a custom Linux VM to be more in control and have a more streamlined process. At the moment a Linux VM is still the most common guest on Genode but we do not necessarily need a full-fledged distribution.
So it consists of a slimmed down Linux kernel that only contains the subsystems and drivers that are required for these particular tests and is based on the 6.6.41 Linux version we also used for our DDE Linux-based drivers. Since the primary target is VBox6, with AHCI configured for block access, we can make due with a slimmed down kernel config. Beside the drivers and subsystems it solely contains the things required for driving a simple busybox-based user-land where a serial-console is used for output (and if need be input).
A minimal linuxrc is provided for driving the init system of busybox that can mount a VBox6 shared-folder to obtain additional configurations and programs. The boot-loader (GRUB2), kernel and the initial userland are part of an .iso file, from which the VM is booted. The block-device is accessed via VBox6's VMDK back-end.
The actual infrastructure for testing is imported into the running VM via the shared-folder. It consists of an init.sh shell script that performs the testing step by step. It sets up the environment in the VM, orchestrates the testing and collects the results. The test programs are imported into the VM via this approach as well and consist of the glibc 2.39 library, dd (coreutils 9.4) and fio 3.39. This variants were chosen to provide the means for potentially comparing the results obtain in this test VM with other distributions.
Having a small test VM allows for fast turn-around times when rebooting the VM. This is done between each test to make sure that each test starts in an controlled environment where the cross-talk is minimized.
The guest output is printed to Genode's LOG service via the serial-console in the VM and by marking the specific steps allows for combining the test with other information, like CPU load and CPU frequency.